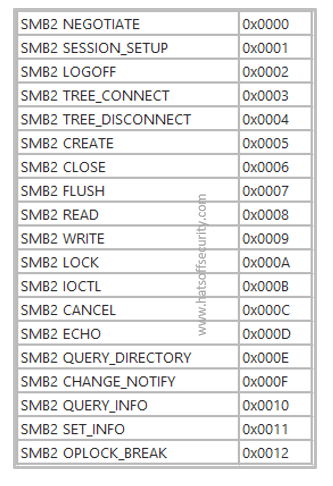
In this post we are going to look at different types of HTTP/1.1 methods. We will leave HTTP/2 methods for another day.
This will be a summary of each method, it is possible to go into great detail with some of these points, but that would get tiresome to read (and write).
What is an HTTP ‘Method’?
With HTTP communication there is often a lot of information being sent backwards and forwards. Some of this is completing previous requests, some is new and occasionally some is erroneous. The client and server both need to quickly be able to see what is happening and how to deal with this communication.
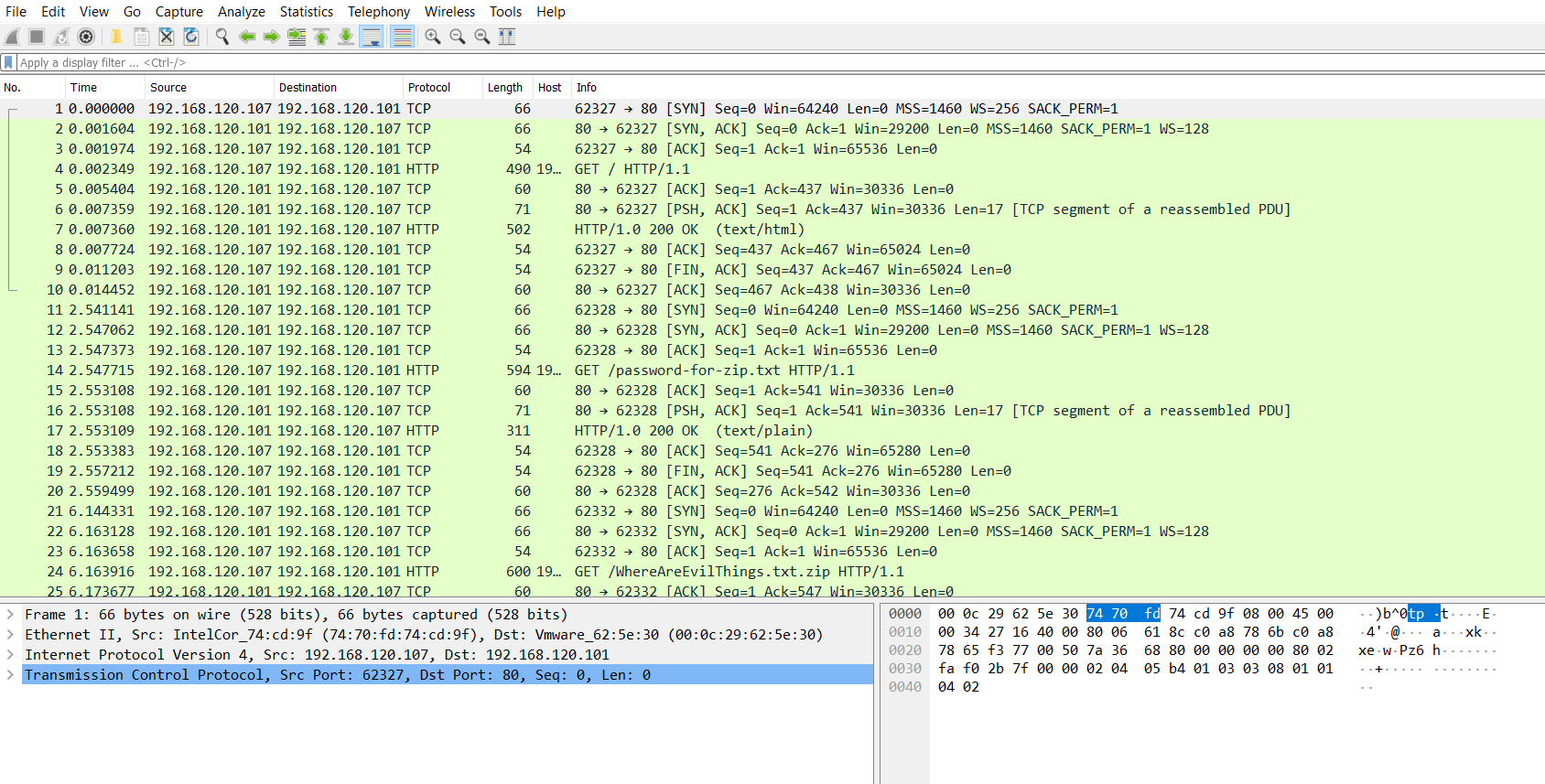
The HTTP method is at the very start of the HTTP communication
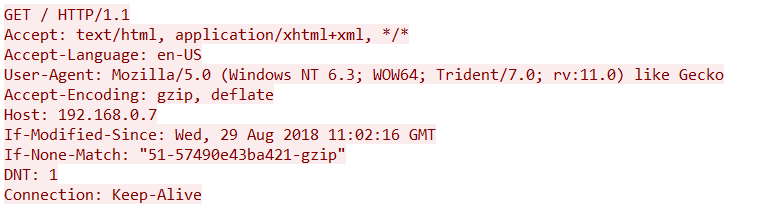
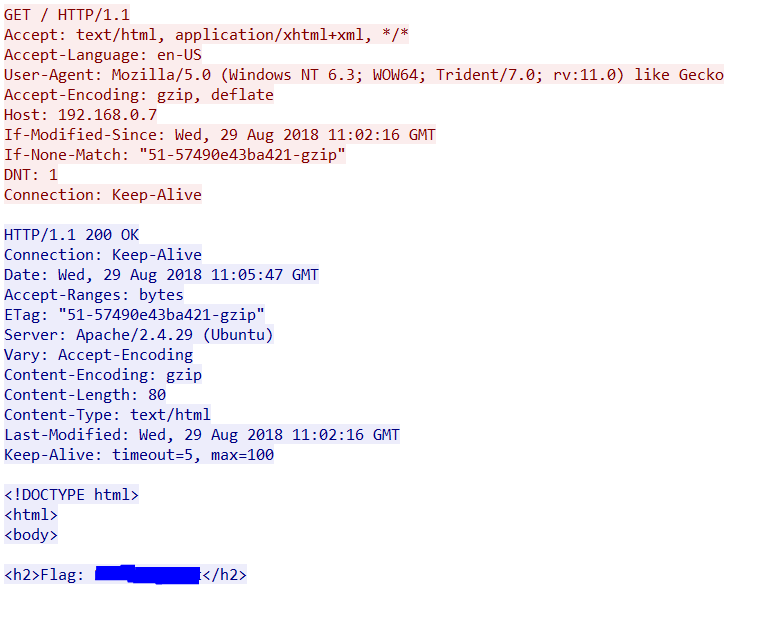
As we can see on the above screenshot the very first word on the top line is GET. GET is an HTTP method. This is the same for any new communication as it allows the server to process the request in an appropriate way as efficiently as possible.
GET
This is the most common request from a user’s perspective. When you loaded this page your browser issues a GET request to the host “hatsoffsecurity.com” with a request for the specific resource. If you are viewing this from the main page the request would look similar to above requesting a forward slash. If you were clicking a link you would be requesting ‘/2019/04/09/http-methods’ as the resource.
Separate GET requests are generated for additional resources on that page, even down to the favicon which shows up in the tab on most common browsers.
Results of a GET request can be held in the browser cache and will appear in the browser history. The GET request itself should not be transmitting any data, only the header.
Side note – this used to display next to the URL, but browser creators removed it to stop people using padlocks to trick people into thinking the site was secure when it was’t
POST
A POST request is used if you are sending data to the server. An example of this could be that you complete a simple form. This data is then sent form the client to the server where it is dealt with depending on the configuration of the server.
This process is slightly more secure than a GET as the data can be sent inside the request. With a GET this data would be sent in the URL which would mean it was recorded in the server logs and in the browser history.
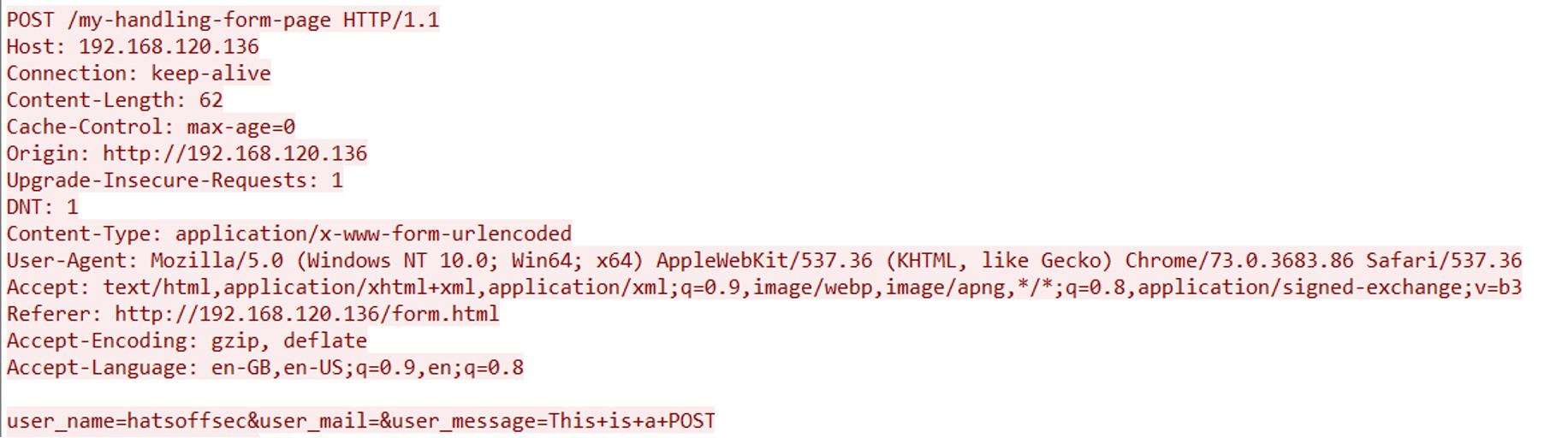
POSTS can also be used to exfiltrate data by an attacker. While this is a very noisy method, it could be used in a ‘smash and grab’ attack; where the attacker has no interest in being stealthy, but instead just wants to be fast.
HEAD
A HEAD request works the same basic way as a GET request, the difference is with the response. The major difference being that the HEAD request only requires the return header and no data.
This is seen quite often with bots. Consider a search engine may index your entire page on an hourly basis, this requires a lot of time and energy on the part of the bot. If they instead send a head request and check for details like Content-Length, Content-MD5, ETag or Last-Modified, then there would be far less work required for sites that haven’t been updated.
PUT
PUT is a way of interacting with the server without causing successive changes. For example if you wanted to create a family tree on a website you could PUT the date of birth on server as this would not change. Even after a family member passes away their birth-date remains the same.
This idea of not changing the data on the server is referred to as ‘idempotent’ and Mozilla have a good Glossary on it here
DELETE
More commonly expected to be seen with an API than with normal user activity, this HTTP method simply deletes the resource that has been identified in the API. Like PUT this is idempotent and after the first time the delete request is actioned by the server subsequent requests will simply return a 404 not found response.
Connect
The CONNECT is most likely to be seen connecting to proxy servers in order to authenticate before the users encrypted browsing session begins. This allows non-SSL breakout proxy servers to monitor web activity. This can also be used for non-encrypted traffic in the same way.
OPTIONS
The OPTIONS header is a way of asking which HTTP methods are allowed by that site. This is now mostly seen in pre-flight CORS checks, which I won’t be covering here.
It is important to realise that OPTIONS should not contain any data and the response should be quite short, simply stating which HTTP methods are accepted. This would be a good candidate for command and control traffic.
TRACE
This is the HTTP version of Ping or Traceroute in the sense that it creates an ‘application layer loopback’ to the recipient sever. It has a ‘Max-forwards’ field that can be decremented at each forward. The recipient simply responds with the same method with 200 as the response code.
This would be unusual to see in a normal user environment, this type of activity should really only be seen in a dev or web-dev environment, or for testing proxy chains for infinite loops.
PATCH
Another API heavy HTTP method, this could be used after a PUT has created a resource on the server. You don’t want to replace the resource, but you do need to update it. As such you can send the amendments using the PATCH method. This is very unlikely to be seen in a user browsing context.
Why do I care?
This is a case of ‘knowing normal’, if you know why a POST might appear unusual vs a GET, you suddenly see a spike in OPTIONS or a domain controller suddenly starts sending out lots of encrypted traffic surrounded by CONNECTS, then you can begin to investigate with the knowledge that it is unexpected behaviour.
It is important to realise that in the immortal words of Phil Hagen; there is no RFC police. These methods are generally agreed upon principles, and there is nothing stopping a developer from using these methods in an unexpected way. Whether that be via an API or a new browser.
Understanding the different methods also allows us to build our knowledge of HTTP and how the internet works from a browsing perspective.