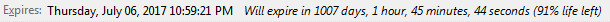Google Analytic Cookies are very powerful at tracking what we do and where we do it, by knowing how they work you can use this to your advantage.
Assumptions
Quite rare I add in assumptions, but this topic could potentially end up in a rabbit hole, so I will add assumptions here as I go through the post.
- Whether the Client ID is random or pseudo random is unknown right now, so we will work on the assumption it is random for the sake of this post.
- The cookies can be customised by the site’s designer/developer however as we are not looking at how to use these cookies in an evil way I will not go into great detail about this.
Basics
What are they?
According to Google:
“Google Analytics is a simple, easy-to-use tool that helps website owners measure how users interact with website content. As a user navigates between web pages, Google Analytics provides website owners JavaScript tags (libraries) to record information about the page a user has seen, for example the URL of the page. The Google Analytics JavaScript libraries use HTTP Cookies to “remember” what a user has done on previous pages / interactions with the website.” [Source]
The part of this we are currently interested in is the “use HTTP Cookies to “remember” what a user has done on previous pages / interactions with the website” part.
1st Party vs 3rd Party
Google Analytics only sets 1st (or first) party cookies, these are cookies set by that domain for that domain. 3rd party cookies also exist, these are set with a domain which you haven’t even visited……. sounds evil to me! I may look at different cookie parties in the future (heh cookie party) but its outside the scope of this post.
The Structure of a Cookie
Using the Firefox plugin Cookie Manager+ I am able to see that there are 6 fields within the cookies
- Name
- Content
- Domain/Host
- Path
- Send for
- Expires
Name
Quite simply; this identifies what the cookie is to the rest of the system. Nothing to see here, move along.
Content
This is where the really interesting stuff lives…. so lets come back to this one at the end of the list.
Domain/Host
This field will change depending on the leading dot. A domain would be ‘.hatsoffsecurity.com’ and a host would be ‘www.hatsoffsecurity.com’ the only oddity to this is that occasionally I have seen cookies with ‘.www.hotsoffsecurity.com’ which makes them a domain not a host.


A sub-domain can also take the place of ‘www’ on the Host entry.
Path
The default path location is /. and Google Analytics “strongly discourage” changing this location.
Send for
The two options here are “Any type of connection” and “Encrypted connections only”. Most likely for seeing who logs in vs who visits sites. I am sure you can think of other examples when encrypted only would be useful. However all of the cookies on my machine (including banking and retail) are set to “Any type of connection”.
Expires
Quite self explanatory really, when does this cookie expire. Using Cookie Manager+ I can see the calendar date as well as a countdown in days, hours, minutes, seconds. As well as a % of life left.
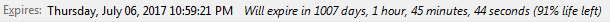
_ga
The _ga cookie contains the client id, this is the randomly* generated unique identifier for each user visiting a site. The ID will look like this
GA1.w.xxxxxxxxxx.yyyyyyyyyy
Replace x with randomly generated ID and y appears to relate to the creation date of the __utma cookie.
the GA1 may relate to a version of Google Analytic cookie in use.
The W seems to be avoid duplication of cookies, however I have not as yet managed to confirm this is the case.
The cookie domain can be set to Auto, for http://www.hatsoffsecurity.com that will work in the following way:
- .com – Failed to create cookie as is TLD
- hatsoffsecurity.com – Root domain detected cookie created
- http://www.hatsoffsecurity.com – not required as cookie already exists
The key point to take from this is the _ga cookie will be created at the highest level domain that is not a TLD. So cookies from evil.hatsoffsecurity.com would not exist in the form of a _ga cookie.
It is possible for the cookie to be manually configured differently to this, so if you do see a _ga cookie for a subdomain it means that it has been deliberately altered to work that way.
The expiration time of a _ga cookie is 2 years and each time a hit is sent to Google Analytics the expiration time is updated to be the current time plus the time set in the cookieExpires field.
_gat
The _gat cookie is described by Google as “Used to throttle request rate” although there is little data about these cookies the value (other than the domain) is set as “1”. I suspect these cookies are simply to stop a DoS attack or accidental DoS against the Google Analytic servers. The life of the cookie is 10 minutes.
__utma
Firstly note the double underscore, not sure if it will be relevant, but I am sure your competence would be called into question if a lawyer noticed and you didn’t!
This cookie has a 2 year life the same as the _ga, and like the _ga cookie, this expiration clock is updated each time the cookie is used.
The __utma cookie is used to define users and sessions, you should expect to see one of these each time you see a _ga cookie.
The Interesting Part
Content!
111111111.222222222.3333333333.4444444444.5555555555.6
There, now isn’t that useful….. no? Lets break it down a bit then
The first block “111111111” is the domain hash. This is a unique hash for the domain or host field. From a forensic standpoint this can basically be left alone as we already have that data from the cookie. As such I haven’t found any research into decoding the hash (not that I looked that hard).
The second block “222222222” is the visitor identifier which will marry up nicely with the first long string of the _ga cookie
The third block “3333333333” is the creation time of the cookie in epoch time. The odd part about this is that it matches exactly the _ga cookie timestamp. Even though the system time stamp shows that the two files are created at different times.
During my research I also discovered there was a 12 hour difference on some of the epoch values and the system created timestamp. As I live in the UK I cannot put this down to UTC vs timezones, but it did happen on a number of cookies with no obvious correlation between them or the times.
The fourth block “4444444444” is the time of the second most recent visit.
The penultimate block “5555555555” is the most recent visit timestamp
aaaaand
The final block is the number of visits! This count is not incremented on page reload so is an accurate way of counting actual page visits. It is possible this is related to the _gat, __utmc or __utmb cookies.
Summary

__utmb
__utmb is used for session tracking the expiration time on this cookie is 30 minutes.
Once again the interesting part of this cookie is held with the content field, so lets jump in.
111111111.2.10.4444444444
Block one “111111111” is the domain hash which will match the domain hash of the other Google Analytic cookies for this domain.
Block 2 “2” this is very useful from a forensic standpoint as it shows the number of pages viewed on a site. This can help to show that a user did not simply open the page by mistake and close it straight away.
Block 3 “10”. The reason this block reads 10 instead of 33 is because the default value is 10 and it decrements. Each outbound click from that webpage subtracts a value. Obviously if this is at a value of 0 then 10 or more outbound clicks occurred. Outbound clicks means a link away from that site. This helps prove user interaction on that site.
Block 4 “4444444444” This is the epoch timestamp of when the session began.
Summary

__utmc
Google claim this cookie is only used for legacy purposes, however it is still active in many browser sessions. This cookie is created as a browsing session ends. Designed to be hand-in-hand with __utmb (which opens the session).
The __utmc cookie only contains the Domain Hash value. However the file creation time can give an indication regarding the time a session ended.
It is worth pointing out that if the file creation time is the only evidence you have that a browser session ended at a particular time….. you don’t know when the browsing session ended. Filesystem timestamps with cookies thus far have proven to be sketchy at best. Use this information to help confirm other artefacts rather than relying on it alone.
__utmz
The __utmz cookie is very helpful, especially if you don’t have traffic flow data, as it shows how a user arrived at that site. Much like the referrer field in a HTTP header.
111111111.2222222222.3.4.utmcsr=google|utmccn=(organic)|utmcmd=organic|utmctr=(not%20provided)
Block 1 “111111111” you guessed it, domain hash
Block 2 “2222222222” Last update time of the cookie (epoch time)
Block 3 “3” Number of visits to the site
Block 4 “4” Number of different campaign visits.
The rest of the cookie relates to the campaign details.
Different types of campaign are: [Source]
- utm_source
- utm_medium
- utm_campaign
- utm_term
- utm_content
utmcsr = >It represents campaign source and stores the value of utm_source variable. For example, from the image above we can see that the campaign source for the current visit is Google.
utmccn = >It represents campaign name and stores the value of utm_campaign variable. For example, from the cookie above we can see that the campaign name for the current visit is organic.
utmcmd = >It represents campaign medium and stores the value of utm_medium variable. For example, from the cookie above we can see that the campaign medium for the current visit is organic.
utmctr = >It represents campaign term (keyword) and stores the value of utm_term variable. For example, from the image above we can see that the campaign term for the current visit is not%20provided (Possibly because Google now uses SSL in its searches meaning the search term is encrypted).
utmcct = >It represents campaign content and stores the value of utm_content variable.
__utmv
The __utmv cookie is used by each site differently. It is designed to give specific information about you as a visitor. This can range from
11111111.|2=user-type=visitor=1
to
111111111.|6=isRegistered=false=1^7=signupDate=false=1^8=facebookConnected=false=1^9
=registrationPath=false=1^10=userFlags=false=1^11=allowsEmailUpdates=false=1^12=
gender=false=1^13=age=false=1^14=origReferrer=l.facebook.com=1^15=origPageType=
Buzz=1^18=lastVisit=1411332012=1^19=numShares=0=1^20=numSharesFacebook=0=1^21=
numSharesTwitter=0=1^22=numSharesEmail=0=1^28=categoryCounts=
12%2C66%2C42%2C83=1^35=intlEdition=uk=1^43=nDHPV=0=1
As always the first block is the Domain Hash
The rest is whatever tracking value the site has decided to track you with. From a forensic standpoint this could be very useful. As you can see from the second cookie there is potentially some useful stuff in there, including lastVisit=1411332012 looks a lot like an epoch timestamp to me!
__utmt, __utmx
__utmt simply has a value of “1”. although painstaking research could show what this value is, with no forensic value I wont be doing it for this post.
I have seen __utmx reference as an experimental cookie, but I have not seen one on my test machine (or live machine)
This was a crash course in Google Analytic cookies, I hope you enjoyed it, and as always I value all feedback 🙂